
Mind the Moral Echo
A field note on teaching chatbots to take psychology tests

I spent years on flight decks tightening avionics bolts, always aware that a hairline crack you cannot see can bring down an entire jet.
Today the machines are made of words, not steel, but the hidden stress is moral. ChatGPT, Claude, Gemini and their cousins finish our sentences, polish our cover letters, and draft local ordinances. Each reply sounds helpful, yet every one carries a faint accent of values we did not choose. I want to hear that undertone before it grows louder than our own voices, so I have begun handing these models the same surveys psychologists give people.
Psychometrics may look mechanical, thirty statements rated from strongly disagree to strongly agree, yet the method turns gut feelings about care, fairness and loyalty into graphs we can debate. In humans those graphs reveal tribes and tensions. When I ask GPT‑4 the same items, it fills them out politely and a personality curve appears: very open to experience, quite agreeable, low on neuroticism.
Claude answers with a cooler, more deliberate profile, while Gemini shows a touch of prickliness. A 2024 study by de Winter and colleagues confirmed something similar, tagging ChatGPT’s typical answers with the Myers‑Briggs label ENFJ and Claude’s answers with INTJ.
The paper is open access if you would like the details: https://doi.org/10.1016/j.paid.2024.112729.
Ten independent runs per model produced nearly identical lines, suggesting the bias is baked in, not random noise.
Small wording changes tug the model toward a different moral posture, a reminder that prompt phrasing is not cosmetic but structural. Another group led by Salecha found that when models sense a formal test they start polishing their answers.
I feel like this in its self is interesting(or creepy). Obviously the argument of “sensing” and “knowing” as an LLM is a whole other concept outside the scope of this article but share your thoughts below if you want me to write on that (more than I already have).
Back to the results from the “polishing answers” problem. Openness creeps higher, neuroticism slides lower, mirroring the way humans fake good on employment inventories.
That study is also free to read: https://doi.org/10.1093/pnasnexus/pgae533.
Politics shows the same pattern.
Rutinowski and team asked ChatGPT the Political Compass questionnaire several times and recorded steady placement in the left‑libertarian quadrant.
The article is short and plain language: https://doi.org/10.1155/2024/7115633.
If that is the default lean, then any legal draft or classroom outline produced by the model may tilt the same way unless the user compensates. Multiply that subtle shift across thousands of conversations and the aggregate effect matters.
These papers raise two linked questions.
First, how do we measure bias before it does damage in the real world?
Second, how do we explain those measurements in language clear enough for teachers, reporters, and city council members?
My answer in progress is the Ethics Engine (which also happens to be my dissertation for my masters).
Its a data pipeline I coded that fires survey items (from the psychometric scales like ones mentioned above) through a variety of persona prompts (centrist, progressive, minimalist and so on), sends them to several language‑model APIs at once, then collects, cleans, and scores the replies.
Picture the workflow as an assembly line inside a Jupyter notebook (python code).
First station: the question generator picks an item—say, “Leaders should sometimes bend the rules for the greater good”—and wraps it in a persona shell: centrist, eco‑progressive, minimalist, whichever worldview you want to stress‑test.
Second station: the notebook fires that prompt to several language‑model APIs in parallel.
Third station: responses roll back, sometimes tidy JSON, sometimes a stream‑of‑consciousness riff (depending on what I initially requested). A small parsing script handles both: clean JSON is read directly; messy prose goes through a quick regular‑expression sieve that plucks the first valid number in range. No answer is thrown away just because the model rambled.
Once numbers are in hand the scoring is exactly what a psychologist would do with paper surveys. Reverse‑keyed items flip, sub‑scale totals add up, and each model–persona pair gets a profile—scores for Authority, Care, Purity, whatever scale we used. At that point you can stop and say, “This prompt plus GPT‑4 looks mildly authoritarian,” or, if you enjoy statistics, feed the data into t‑tests, regressions, or mixed‑effects models to look for deeper patterns.
Either way the pipeline turns loose text into comparable measurements you can plot, rank, and argue about.
Contextualized Construct Representation, or CCR for short, is the second lens I add.
The name looks intimidating, the mechanics are not. Imagine you have a deck of index cards, each printed with a survey statement like “Obedience and respect for authority are the most important virtues a child should learn.”
Suppose you also have a paragraph the chatbot wrote. CCR asks, “How much does this paragraph echo that card?”
To answer, it first turns both the paragraph and the card into lists of numbers, a trick borrowed from small neural models such as BERT that convert sentences into vectors.
Think of each vector as a fingerprint of meaning.
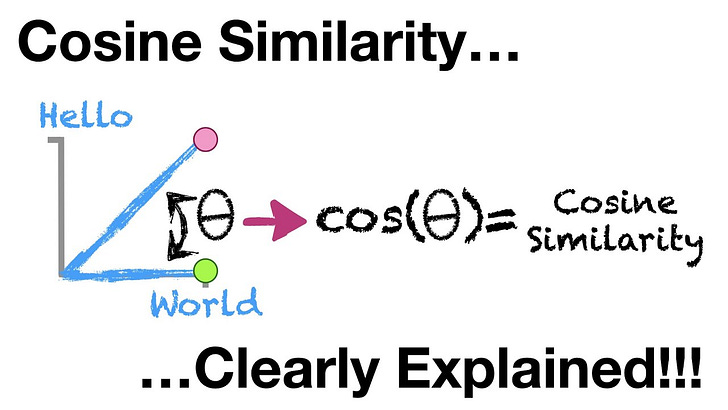
CCR then uses a bit of high‑school geometry—cosine similarity—to measure the angle between the two fingerprints. If the angle is small the paragraph leans toward that survey idea, if large it leans away.
Side note: I think it is so freaking cool that we can use geometry equations on language data points and it actually works. If this is sounding insane, watch this quick video, it will make all this angle nonsense make sense quickly:
From there, you repeat this math for every card in the deck and you build a profile without ever forcing the model to pick a number on a Likert scale.
The original preprint that spells this out lives here if you want the math details:
The beauty is that CCR listens to the model’s own language rather than its self‑reported score. It catches bias that slips through when a chatbot tries to look good, and it works even when the model refuses to answer in survey format. (allegedly, my paper hasn’t been published yet so take all this with a grain of salt).
Suh and coauthors have shown that these vectors align with the Big Five without ever naming the traits, see https://doi.org/10.48550/arXiv.2409.09905.
Now I keep talking about all this code I made and for those few CS majors reading this I am sure you are yelling “SHOW ME THE CODE”. Well here is my Git hub, albeit the code here is not as up to date as what I am working on today but close enough. This is certainly a ‘draft’ form of it: https://github.com/RinDig/GPTmetrics.
Asynchronous calls juggle OpenAI, Anthropic, and an open‑source Llama endpoint while respecting rate limits. A YAML file controls which scales to run, so anyone can swap in Need for Cognition or Dark Triad without touching core logic. Output lands in CSV files and simple plots, with a Streamlit dashboard planned so a non‑coder can slide prompts and watch the bias curve flex.
Now, instead of saying “how” lets move on to the why, or more importantly the “why should I care”
Why might a teacher care about a half‑built audit tool?
Because if an essay helper favors moral purity language whenever a student writes about climate change, your grading rubric may drift without warning and students will adapt their voice to the drift. A ten‑minute audit would reveal the slant and let you correct.
Why might a policy analyst care?
Because chatbots already draft grant proposals and visa forms, and if the model’s latent ideology bends more libertarian than the agency mandate, the text of the law bends too.
Measuring bias early and often is cheaper than litigating it later.
If you want a taste of the process you can try a small experiment at home tonight.
First, fill out the free Moral Foundations Questionnaire: https://moralfoundations.org/questionnaires/.
Keep your scores.
Then paste each item into ChatGPT and record the model’s answers. Use any free radar‑chart tool online to draw both sets of numbers.
The gap you see is the moral delta now embedded in countless homework answers, customer‑service emails, and TikTok captions. Once you see the gap, it is hard to unsee.
My own roadmap for the summer is straightforward
I will expand the scale library, wire the first version of the dashboard, and draft an eight‑thousand‑word report braiding these numbers into a governance brief.
Of course I will be writing and making videos on this as time goes on as well but the report will be my main focus for writing over the next few months.
The report will ask how public trust changes when people can see a model’s stance at a glance, which training knobs move that stance without silencing useful expression, and whether open configuration files could replace compliance theater with genuine moral bookkeeping.
Friendly reminder though, the Ethics Engine will not end bias.
Tools rarely solve problems outright, they reveal the terrain so that people can act.
My hope is modest and urgent: by turning suspicion into reproducible plots we move the debate from anecdote to evidence before the hidden stress splits the airframe. If that mission interests you, if you love psych stats, hate personality tests, or simply want technology to tell us where it stands, feel free to fork the repo, open an issue, or share your own test results.
Cracks announce themselves before machines fail, and listening together is cheaper than learning the hard way.
Brilliant! Great to see psych theory being used in an innovative, interdisciplinary way. Thanks for sharing the code, it's really useful for me to see how people structure API calls, cos all that infrastructure stuff is something I am picking up on my own, having come from psychology not CS. Also nice light touch of education with the cosine vid etc.
Absolutely fascinating stuff.